1. Introduction: What is Machine Learning?
For decades, building software meant handing a computer a rigid set of step-by-step instructions. If a scenario wasn't explicitly coded by a human engineer, the program couldn't handle it. Machine Learning (ML) flips this entirely. As a dynamic branch of Artificial Intelligence (AI), ML gives systems the ability to learn from raw data, spot hidden patterns, and make decisions with minimal human intervention.
Instead of being programmed, these models are trained. They adapt to new inputs and grow more accurate over time, allowing them to generalize past experiences to tackle unseen future scenarios.
This isn't a new concept, though it feels incredibly modern. Back in 1959, Arthur Samuel defined ML as giving computers the ability to learn without explicit programming. Tom Mitchell sharpened this in 1997 with a formula: a program learns from "experience" (data) regarding a "task" (the goal) and a "performance measure" (the success rate), improving as it gathers more experience.
2. A Brief History of Machine Learning
The road to modern AI didn't happen overnight. It is the result of decades of breakthroughs:
1950s–1960s (The Birth): The 1956 Dartmouth Summer Research Project officially birthed AI. Early innovations like the Perceptron laid the groundwork for pattern recognition.
1970s–1980s (Trees & Nets): The focus shifted to practical, interpretable models like decision trees (ID3). Meanwhile, the popularization of backpropagation allowed multi-layer neural networks to learn complex relationships.
1990s (Stronger Algorithms): Support Vector Machines (SVMs) dominated high-dimensional classification. Ensemble methods like Bagging (1996) and AdaBoost (1997) proved that combining multiple models significantly reduces errors.
2000s (Web-Scale Learning): The internet boom provided massive datasets, bringing probabilistic graphical models into the spotlight for handling uncertainty and sequential data.
2010s (The Deep Learning Revolution): Deep convolutional neural networks changed everything. AlexNet crushed image recognition benchmarks in 2012, and AlphaGo defeated a human world champion in 2016.
2020s (Generative AI & The Edge): We are now living in the era of foundation models (like GPT-4). ML is also moving directly onto smartphones via edge computing, boosting real-time processing and privacy.
3. Real-World Applications Across Domains
Machine learning isn't just theory; it is actively driving data-driven decisions across almost every major industry.
Healthcare: Computer vision models are now capable of detecting diabetic retinopathy from retinal images with over 90% sensitivity in large-scale screenings, drastically reducing the diagnostic burden on medical professionals.
Finance: Gradient boosting algorithms process credit risk scoring to offer early warnings on defaults, allowing financial institutions to manage risk proactively.
Retail & E-commerce: Recommendation engines analyze your clicking and buying habits. Platforms like Amazon and Netflix attribute up to 35% of their total sales directly to these personalized ML suggestions.
Smart Cities & Climate: Real-time ML traffic optimization can decrease urban commute times by 18%. In climate science, algorithms downscale global models to deliver highly detailed, localized forecasts for regional planning.
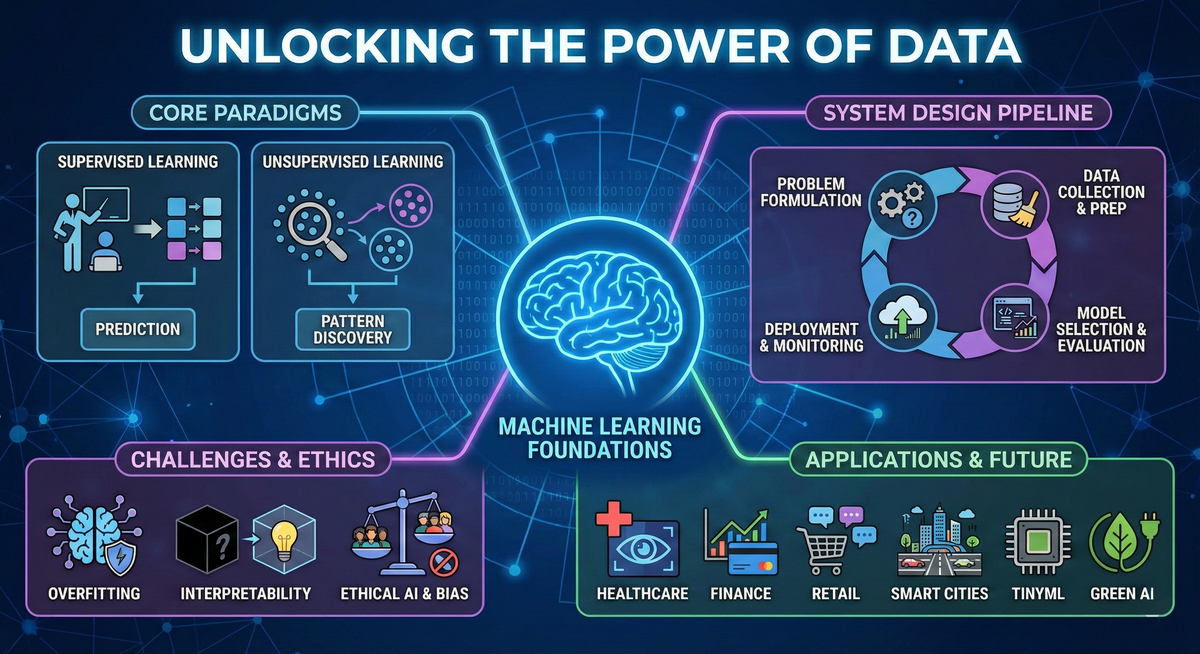
4. Core Paradigms: Supervised vs. Unsupervised Learning
To understand how machines learn, you have to look at the two main ways we teach them.
Supervised Learning ("Learning with Answers") Here, the model acts like a student studying with an answer key. The training data comes with "labels"—the correct answers. The model looks at the input features, makes a prediction, and checks the label to see if it was right.
Common tasks: Predicting numbers (Linear Regression) or categorizing data (Decision Trees, SVMs).
Real-world example: An email spam filter learning from thousands of messages manually tagged as "spam" or "not spam."
Evaluation: Success is tracked using metrics like Accuracy, Precision, Recall, and AUROC.
Unsupervised Learning ("Learning without Answers") In this paradigm, the algorithm is handed a massive pile of raw, unlabeled data and told to find the hidden structure on its own.
Clustering: Algorithms like K-Means group similar data points together. A streaming app might use this to naturally cluster users into "indie rock fans" or "jazz listeners" based entirely on playback habits.
Dimensionality Reduction: Techniques like PCA simplify overwhelmingly complex datasets into fewer features, which is crucial for data visualization.
5. Designing a Robust Learning System
Building an ML solution is a structured workflow, not just a coding exercise.
Problem Formulation: Define the business goal, the required inputs/outputs, and exactly how you will measure success.
Data Collection & Preprocessing: Gather data from databases or sensors. Clean it by handling missing values and outliers. Preprocessing involves scaling numerical features (so no single number dominates the model) and encoding categories.
Model Selection & Evaluation: Test various algorithms. Use hyperparameter tuning and cross-validation to gauge how the model will perform on brand-new data.
Deployment & Monitoring: Push the model live using strategies like A/B testing or Canary Releases (rolling it out to a small group first). You must continuously monitor for "data drift"—when real-world data changes over time, causing the model's accuracy to tank.
6. Navigating Technical Challenges
Practitioners constantly battle a few major technical hurdles:
Overfitting and Underfitting: Overfitting happens when a model memorizes the training data perfectly—including the random noise—but fails completely when shown new data. Data scientists combat this using Regularization techniques (like L1/L2) to penalize overly complex models.
Interpretability: Deep neural networks are notorious "black boxes." In high-stakes fields like finance or medicine, people need to know why a decision was made. Tools like SHAP and LIME help explain exactly which features triggered a specific prediction.
Scalability: Massive datasets require models to be incredibly efficient. Techniques like Distributed Training (splitting the workload across multiple machines) keep training times reasonable.
7. The Primacy of Data
A machine learning model is absolutely useless if the data feeding it is garbage.
Improving data quality—ensuring accuracy, completeness, and consistency—often yields a much higher performance boost than switching to a fancier algorithm. Simply cleaning out duplicate records can dramatically shift your results.
When data is scarce or imbalanced, engineers get creative. They use techniques like SMOTE to generate synthetic samples for underrepresented categories, or Generative Adversarial Networks (GANs) to create highly realistic synthetic images that preserve patient privacy while still training the model.
8. Emerging Trends and Ethical AI
As ML embeds itself deeper into our daily lives, we have to look closely at its societal footprint.
Ethical AI & Bias: ML models learn from human data, which means they can easily adopt human biases. Without strict fairness protocols, models can demonstrate stark disparities—for instance, historical facial recognition datasets have resulted in error rates varying by up to 30% between different racial and gender demographics. Modern systems must be audited for fairness, secured against adversarial attacks, and built using privacy-preserving techniques like Federated Learning.
TinyML: We are shrinking models to fit on resource-constrained devices like IoT sensors and smartwatches. This keeps data on the device, dropping latency and boosting privacy.
AutoML: Automated Machine Learning is doing the heavy lifting of model selection and tuning, allowing non-engineers to leverage AI for their own businesses.
Green AI: Training massive AI models consumes vast amounts of electricity. Green AI pushes for model pruning and energy-efficient hardware to cut down the carbon footprint of digital innovation.
Conclusion
Machine Learning has graduated from theoretical mathematics to the core engine powering modern technology. By understanding the supervised and unsupervised paradigms, building resilient data pipelines, and actively prioritizing transparent, ethical systems, developers can unlock AI's true potential. From mapping global climate shifts to organizing your morning inbox, the foundational principles of Machine Learning will continue to write the future of digital life.






